广度优先遍历
广度优先搜索(BFS)算法以宽幅运动遍历图形并使用队列记住在任何迭代中发生死角时获取下一个顶点以开始搜索。
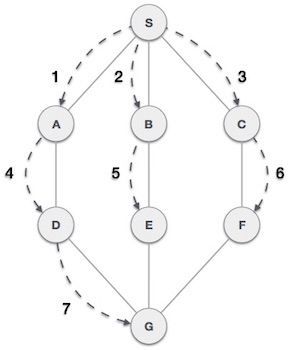
如在上面给出的示例中,BFS算法首先从A到B到E到F,然后到C和G,最后到D.它采用以下规则。
规则1 - 访问相邻的未访问顶点。 将其标记为已访问。显示它。将其插入队列中。
规则2 - 如果未找到相邻顶点,则从队列中删除第一个顶点。
规则3 - 重复规则1和规则2,直到队列为空。
| 步 | 穿越 | 描述 |
|---|---|---|
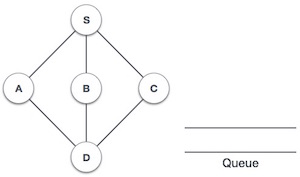
| 1 |
|
初始化队列。 |
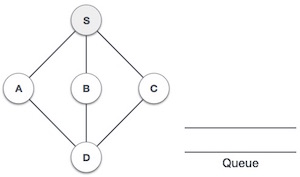
| 2 |
|
我们从访问 **S** (起始节点)开始,并将其标记为已访问。 |
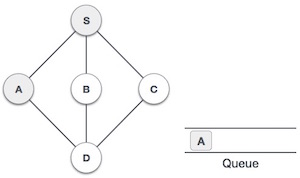
| 3 |
|
然后我们从 **S** 看到一个未访问的相邻节点。在这个例子中,我们有三个节点,但按字母顺序我们选择 **A** ,将其标记为已访问并将其排入队列。 |
| 4 |
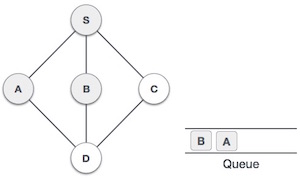
|
接下来,从未访问的邻接节点 **小号** 是 **乙** 。我们将其标记为已访问并将其排入队列。 |
| 5 |
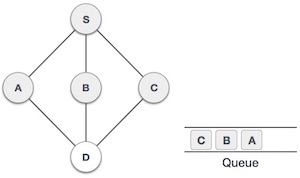
|
接下来,从未访问邻接节点 **小号** 是 **Ç** 。我们将其标记为已访问并将其排入队列。 |
| 6 |
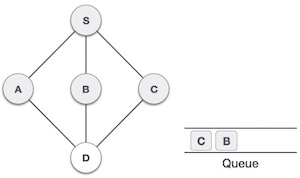
|
现在, **S** 没有未访问的相邻节点。所以,我们出队,并找到 **一个** 。 |
| 7 |
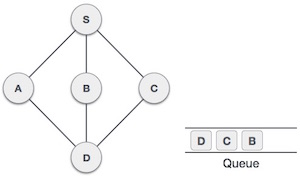
|
从 **A** 我们有 **D** 作为未访问的相邻节点。我们将其标记为已访问并将其排入队列。 |
在这个阶段,我们没有未标记(未访问)的节点。但是根据算法我们继续出列以获得所有未访问的节点。当队列清空时,程序结束。